

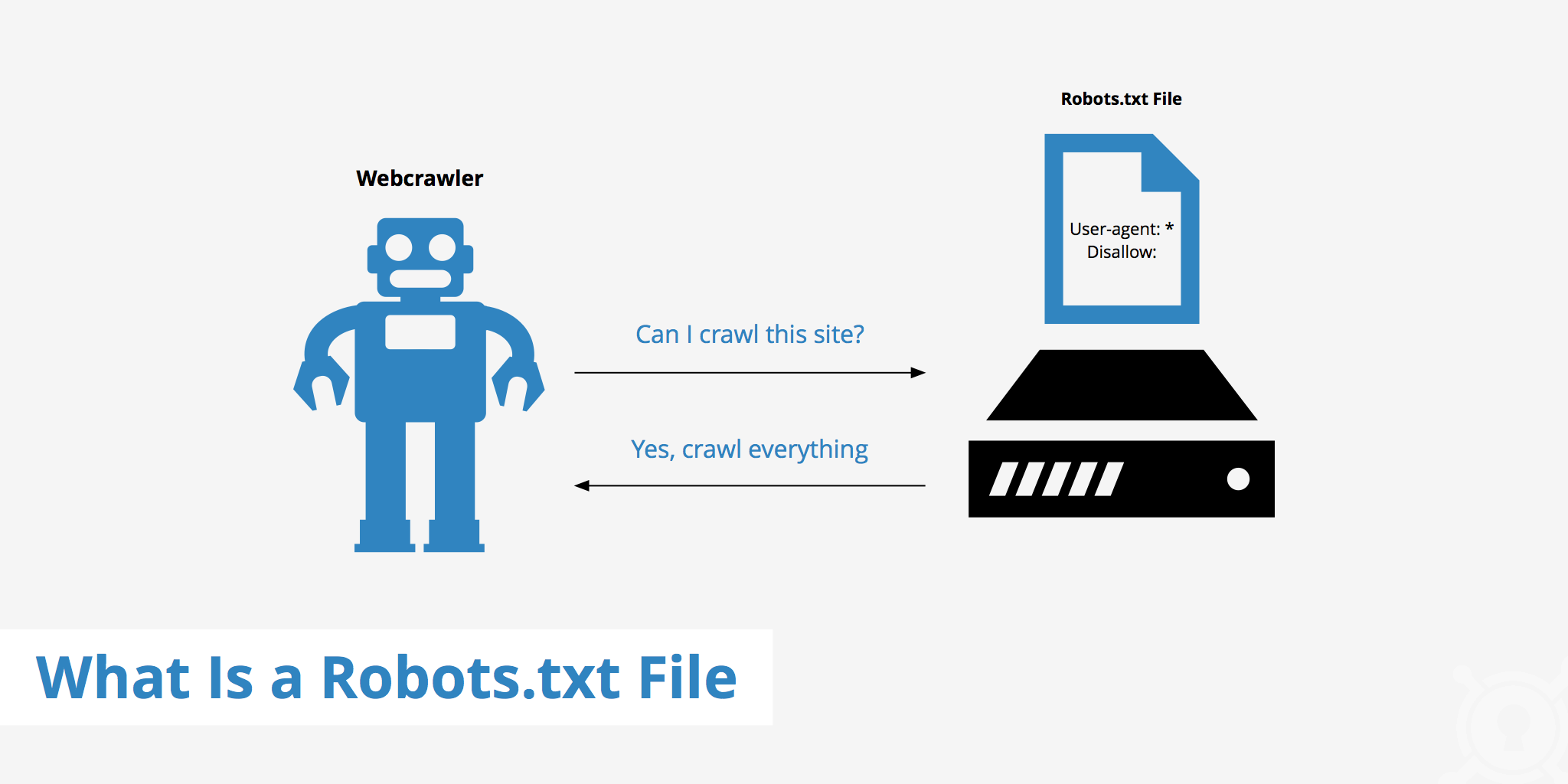
In the vast expanse of the internet, where websites sprawl like cities and data flows like rivers, there exists a humble but crucial file that often goes unnoticed: robots.txt. This unassuming text file serves as a gatekeeper, controlling how search engines and other web robots navigate and index a website’s content. Let’s embark on a journey to explore the significance of robots.txt and how it shapes the digital landscape.
Understanding Robots.txt
Robots.txt is a simple text file located at the root directory of a website. Its primary purpose is to communicate with web crawlers, informing them which parts of the site they are allowed to access and index. This file contains directives that specify user-agent rules, indicating the behavior that various bots should follow when traversing the site.
Directives and Syntax
Robots.txt operates on a set of directives, each serving a specific function:
-
User-agent: This directive specifies the web robot to which the following rules apply. For example, “*” represents all robots, while specific user-agent names target particular bots like Googlebot or Bingbot.
-
Disallow: Disallow tells robots which parts of the site they are not allowed to access. For instance, “Disallow: /private” instructs bots to avoid crawling any URLs starting with “/private.”
-
Allow: Allow works in conjunction with Disallow, overriding any previous restrictions and permitting access to specific areas.
-
Crawl-delay: This directive sets a delay in seconds between successive requests to the server from the same bot. It helps prevent overloading the server with too many requests.
Crafting an Effective Robots.txt File
Creating a robots.txt file involves careful consideration to ensure it serves its intended purpose without inadvertently blocking important content. Here are some best practices:
-
Prioritize Security and Privacy: Use robots.txt to restrict access to sensitive or confidential areas of your site, such as admin panels or personal data directories.
-
Optimize for SEO: While robots.txt can control bot access, it doesn’t directly influence search engine rankings. However, by guiding crawlers away from duplicate content or irrelevant pages, it indirectly contributes to a better SEO performance.
-
Regular Updates: As your website evolves, so should your robots.txt file. Regularly review and update it to reflect changes in site structure or content.
-
Test and Validate: After creating or modifying your robots.txt file, use online validation tools or Google’s Search Console to ensure it’s formatted correctly and achieving the desired results.
Transparency and Collaboration
While robots.txt empowers website owners to manage bot access, it’s essential to maintain transparency and collaboration within the digital ecosystem. Openly communicating with search engines through robots.txt fosters a symbiotic relationship where bots efficiently index relevant content while respecting site owners’ preferences and directives.
Conclusion
In the intricate web of the internet, robots.txt serves as a guardian, guiding web crawlers through the digital maze while safeguarding the integrity and privacy of websites. Understanding its role and leveraging its directives effectively empowers website owners to shape their online presence and optimize their interactions with search engines and other web robots. So, the next time you embark on a digital journey, remember the quiet yet indispensable companion: robots.txt.




